

Ranking the best AI for education: a new study
Which AI is the best one to learn? A new benchmark tested 97 AI models on real pedagogy and there are some surprises among the results.


Everyone’s got a study buddy now: ChatGPT, Claude, Gemini… even your calendar app pretends to be an AI coach now! But if you’re serious about learning, there’s a question that matters more than the next app adding ‘AI-powered’ to its tagline: which one actually knows how to teach?
Last week, I talked about three paradoxes of AI in education: those structural challenges that show up when we use AI to learn. Every model handles these paradoxes in its own way. But which one actually does it better?
A new benchmark has finally given us a real answer. And no, it’s not based on vibes, popularity or yet another LinkedIn post claiming to have finally found “the” model.
It’s based on pedagogy.
The first benchmark that actually cares about learning
Most AI benchmarks test content knowledge. They’re good at asking: does this model know biology? Or law? Or whether Napoleon was short? What they don’t ask is: can this model teach any of that stuff well?
A new study, by Lelièvre et al. published only some weeks ago, changes that. It introduces the Pedagogy Benchmark, a dataset made up of real teacher certification questions from Chile’s Ministry of Education. These aren’t trivia questions, they assess teaching strategies, classroom management, assessment design and even special education knowledge.

There are two parts:
CDPK (Cross-Domain Pedagogical Knowledge): 920 multiple-choice questions focusing on learning theories, instructional design and teaching practices for learners of different ages.
SEND (Special Education Needs and Disability): 223 questions focused on inclusive education and specific pedagogy for learners with special needs.
Want to know the kind of questions AI had to face? Here’s the general idea. Some questions described a task and then asked “Which performance of the student would demonstrate the achievement of the learning objective?”, then giving four multiple-choice options. Some others described a learning objective and asked “What activities are most appropriate to evaluate it in Year 2?”, etc.
This isn’t only about facts. It’s about understanding what learning looks like. And it’s a lot harder to fake!
Who topped the leaderboard?
The benchmark tested 97 large language models. Some were big and shiny. Some were scrappy and efficient. Here’s the top 10:
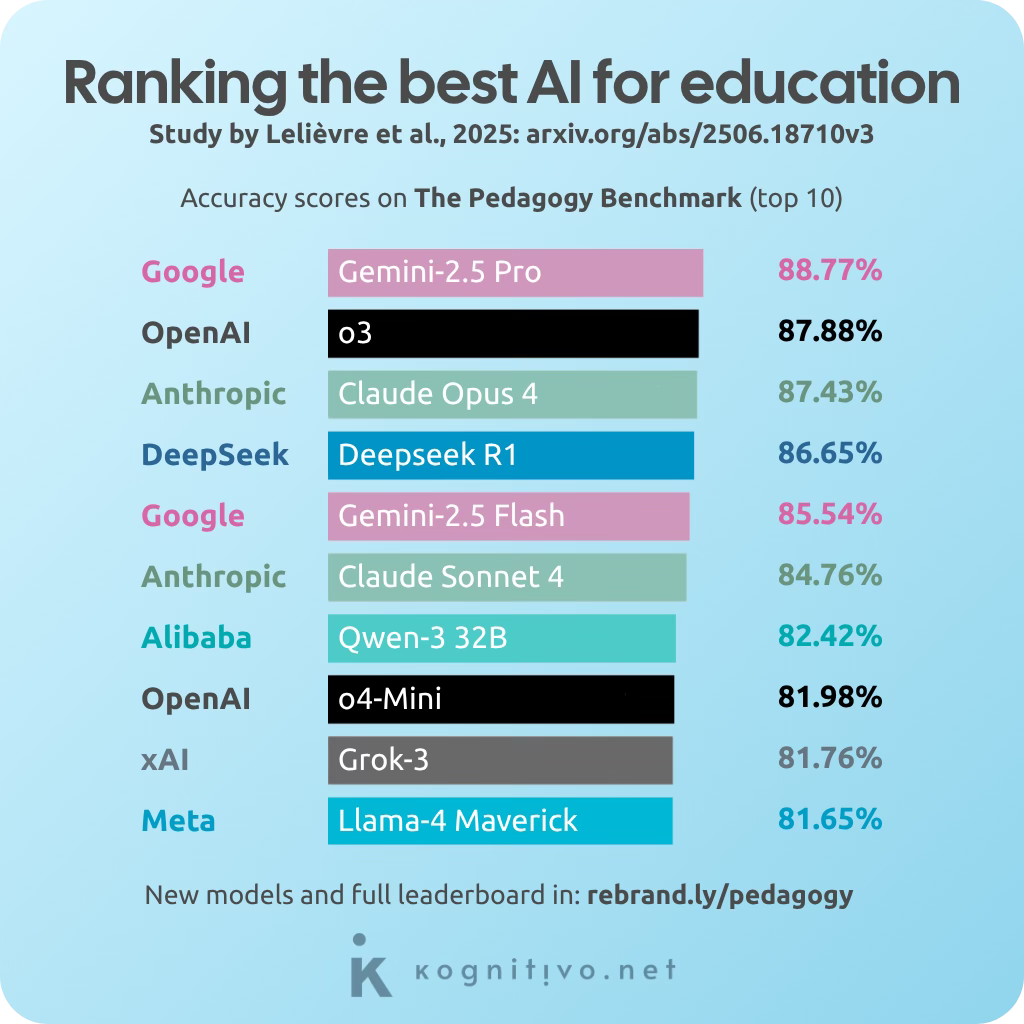
You’ll find more models on the leaderboard than in the study, as the benchmark is regularly applied to newly released ones! The leaderboard also includes a benchmark on content knowledge.
But the results are clear: Gemini, ChatGPT and Claude top the list, with Google’s Gemini-2.5 Pro taking the first place! You might be wondering: how good is 88.77%, really? Consider that the reference of an average teacher’s accuracy is 50% based on past national exam scores.
Some of these AIs are now scoring nearly 90% on actual teacher assessments, which is quite impressive. But the opposite is also true: at least 10% of the answers of every AI model were completely wrong when it came to assessing their pedagogical knowledge. This means that no AI proved to be error-free.
Not to gloat over anyone's misfortunes, but here I drop that at the bottom of the ranking is Meta’s AI Llama-3.2 1B, which only scored 28.03%. In their defense, the newer version Llama-4 Maverick performed much better at 81.65%. Somewhat disappointing is Perplexity’s Sonar at 70.75%, not even making it to the top 25.
Also note: when it came to Special Educational Needs and Disabilities (SEND), performance dropped. Even top models did worse here than on general pedagogy, dropping by an average of 3%. If we want AI to support all learners, this gap needs to close.
OpenAI’s o3 vs GPT-4o: a cautionary tale
One of the most unexpected results? OpenAI’s o3 outperformed GPT-4o by nearly 10 points. Interestingly enough, o4-mini also outperformed GPT-4o! That’s not just surprising… it’s a bit embarrassing for the flagship model.
87.88% – o3 (OpenAI)
81.98% – o4-mini (OpenAI)
78.31% – GPT-4o (OpenAI)
You’d expect GPT-4o to be better. It’s newer. It’s faster. It’s got the marketing push. But o3 (an older, slower model) was smarter when it came to pedagogy. The authors don’t spell out why, but they hint at the real culprit: reasoning. o3 had better fine-tuning for chain-of-thought and instruction-following tasks, which matter a lot when you’re asked to identify learning strategies, not just spew facts.
Let this be a lesson: newer ≠ more pedagogically competent. And definitely faster ≠ better. Here we can clearly see the consequences of the paradox of efficiency.
Reasoning beats raw power
Another trend stood out: the best models were all “thinking models”, fine-tuned for step-by-step reasoning. Even though the benchmark used multiple-choice questions, those that encouraged internal reflection (a.k.a. “think before you guess”) scored higher.
This is exactly the paradox of outsourced thinking in full action. In a world that rewards hot takes and instant answers, it’s refreshing (and kind of poetic) that the better teachers were the ones who took a moment to think.
What this means for learners
So, if you’re using AI to learn, what should you take away?
Pick tools that know how to teach, not just what to say. A model that helps you discover the answer beats one that blurts it out in the most convincing way. This new benchmark is gold when it comes to picking your AI study buddy!
Some AIs are better teachers in specific areas. The dataset includes questions per subject. While Gemini-2.5 Pro beats everyone in Maths, Science and Technology, o3 actually tops the Social studies leaderboard! You can use the filter per subject on the leaderboard (top left corner).
Performance isn’t just about model size. Don’t fall into the trap of “it’s newer and more expensive, therefore it must be better”. Smaller, smarter and cheaper might be better for your needs.
Don’t forget that, at the end of the day, you also need to do your part! No matter what AI you use, if it’s not making you think, then you know it’s not doing the job. You want an AI that gives you desirable difficulties, the productive struggle that makes learning stick!
What this means for educators and edtech teams
If you’re building tools, not just using them, here are 4 takeaways:
Open-source is rising. Deepseek R1 and the Qwen series (from Alibaba) delivered strong performance at a fraction of the cost. You don’t need a $100 million model to build a smart tutor.
Cost vs performance matters. The benchmark included a full value frontier showing that models like Qwen 8B get you >70% accuracy at $0.035 per million tokens. That’s wild. And budget-friendly. You’ll find a breakdown graph of accuracy vs cost on the leaderboard (scroll down).
On-device models are catching up. Gemma 3n E4B (Google) and LFM-7B (Liquid AI) are optimized for phones and laptops and scored >60%. That means local, offline AI tutors may be here sooner than you think. This is relevant regarding user privacy, as these models don’t send the user’s information to any servers.
There’s no way around fact-checking. Even if the study shows promising results, every edtech professional should be worried when reading that no model managed to avoid 10% of its answers being complete nonsense. Sadly, the core issue might be bigger than we think.
Warning: the benchmark isn’t about practice
There’s a small “but”. The authors of the benchmark openly acknowledge that it’s based on pedagogical knowledge, not on pedagogical practice. A properly scientific benchmark would require experts set up experiments and assess the actual outcomes of learners using every AI model. This benchmark, however, is built on what every AI model “claims” about pedagogy in multiple choice questions, which certainly isn’t the same as assessing the actual practice of an AI teaching students.
The authors explain that such a setting wouldn’t be scalable, as it would be too difficult to replicate and update for every new AI model. This is indeed relevant when it comes to tackling the paradox of openness, which can hardly be observed by asking direct questions to the AI models.
In any case, the questions used are very praxis-oriented (as we saw) and the benchmark certainly provides a solid guideline, grounded in actual pedagogy. The value it provides by giving us a dynamic, ever growing leaderboard is certainly worth the compromise.
Choose wisely
If you’re wondering whether I paused mid-article to re-rank my own study tools… obviously! This benchmark gives us more than a scoreboard that will get progressively updated. It gives us a compass. I’m not saying I printed the benchmark leaderboard and taped it to my wall, but… I’m also not not saying it!
The AI that’s best for learning isn’t necessarily the fastest, newest or most hyped. It’s the one that understands how people learn and can teach accordingly.
Keep learning
Prompt suggestions. Always ask follow-up questions
I want to pick the best AI model to help me study. Based on the pedagogy benchmark, which one should I use for my specific subject or learning goal?
Explain why older or smaller models like o3 or DeepseekR1 might be better for learning than newer, more powerful ones. How should that change my choice of study buddy?
Act as a tutor and test me on the key findings of the pedagogy benchmark study for AI models. Ask me 6 questions, one at a time, only continuing when I answer. Make them progressively harder.
Links
📑 Benchmarking the Pedagogical Knowledge of Large Language Models: Here’s the link to the study I’ve discussed in this article. You can access it on “View PDF”. The last version of the study, at the moment of writing, is from July 1st 2025. The article is shared under a cc-by license.
📊 The Pedagogy Benchmark leaderboard: This is a good website to bookmark on your browser and keep coming back to whenever a new AI model comes out!


Quite interesting. As you mention, the benchmark outlines only what the models know ‘about’ teaching, not whether they can actually do the teaching. I would love to see a study of that, perhaps limiting it to the Top 3 candidates from this survey.